[머신러닝] 강아지, 고양이 분류
Goal
- Cat and Dog 데이터셋을 전처리 할 줄 안다.
- ResNet50을 사용해서 학습시킨다.
- 저자가 키우는 강아지를 분류한다.
데이터 전처리
figure_data = '/content/drive/MyDrive/cat-and-dog'
num_classes = len(os.listdir(figure_data))
BATCH_SIZE = 4
EPOCH = 100
X = []
Y = []
cnt =0
for idex, figure_datas in enumerate(os.listdir(figure_data)):
label = [0 for i in range(num_classes)
label[idex] = 1
figure_dir = os.path.join(figure_data, figure_datas)
for image_name in os.listdir(figure_dir):
image_path = os.path.join(figure_dir,image_name)
img_RGB = load_img(image_path, target_size=(224, 224))
img_RGB = img_to_array(img_RGB)
X.append(img_RGB)
Y.append(label)
cnt +=1
print(cnt)
if(cnt % 2000 == 0):
break
X = np.array(X)
Y = np.array(Y)
x_train, x_test, y_train, y_test = train_test_split(X,Y, test_size = 0.2, shuffle = True, random_state = 777, stratify=Y)
cnt 가 2000일시 break를 쓴 이유는 이미지가 너무 많아서 구글 코랩으로는 메모리가 버티질 못했다..ㅜㅜ
모델 구성
base_model = ResNet50V2(include_top=False, weights=None, input_shape=(224, 224, 3), classes=2)
drop = layers.Dropout(0.5)(base_model.output)
pool = GlobalAveragePooling2D()(drop)
drop2 = layers.Dropout(0.5)(pool)
layer1 = Dense(units = 2, activation='softmax', kernel_regularizer = tf.keras.regularizers.l2(0.001))(drop2) #final layer with softmax activation
model = Model(inputs=base_model.input, outputs=layer1)
모델 학습
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(x_train, y_train, epochs=50, batch_size=100, shuffle = True, validation_data=(x_test, y_test), verbose = 1)
Accuracy 그래프
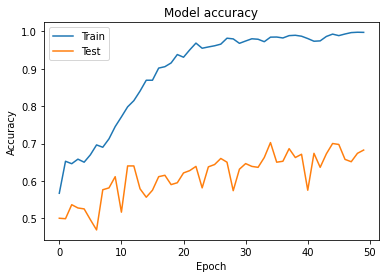
학습결과(강아지, 고양이)
강아지

고양이

저자 강아지

결론
- 본래 데이터셋은 총 25000장이지만 4천장 밖에 학습하지 못해 정확도가 높진 않아 보인다.
- Labeling이 정확하지 않아서 배경에 영향을 많이 받는 것 같다.
학습을 통해 배운점
#넘파이 형식으로 저장
from numpy import save
save(Path, X)
save(Path, Y)
#넘파이 형식으로 로딩
from numpy import load
X = load(Path)
Y = load(Path)
#모델 저장 및 불러오기
model.save(Path)
load_model(Path)
지정된 경로에 image와 label을 Numpy 형식으로 저장하고 불러올 수 있다.