[머신러닝]Cifar-10 데이터 셋 CNN 학습
데이터 셋

클래스 총 10개
데이터 불러오기 및 전 처리
tf.keras.datasets.cifar10.load_data()
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
num_classes = 10
EPOCH = 10
BATCH_SIZE = 4
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
x_train = x_train/255.0
x_test = x_test/255.0
모델 구성
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))
모델 시각화
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
flatten (Flatten) (None, 1024) 0
dense (Dense) (None, 64) 65600
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 122,570
Trainable params: 122,570
Non-trainable params: 0
_________________________________________________________________
모델 학습
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
history = model.fit(x_train, y_train, epochs=EPOCH , batch_size = BATCH_SIZE, validation_data = (x_test, y_test), verbose = 1)
Epoch 1/10
12500/12500 [==============================] - 58s 4ms/step - loss: 1.5071 - accuracy: 0.4502 - val_loss: 1.2627 - val_accuracy: 0.5466
.
.
.
Epoch 10/10
12500/12500 [==============================] - 45s 4ms/step - loss: 0.7198 - accuracy: 0.7468 - val_loss: 1.0584 - val_accuracy: 0.6620
모델 평가
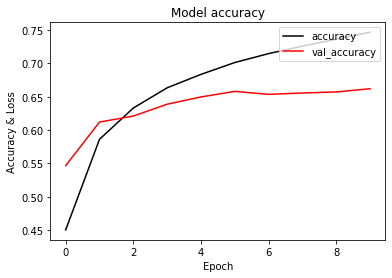
accuracy : 0.7468
val_accuracy : 0.6620
학습을 통해 배운점
categorical_crossentropy : 다중 분류 손실함수로, One Hot encoding 된 결과로 나온다.
sparse_categorical_crossentropy : 위와같은 다중 분류 손실함수 이지만 정수 클래스 타입이라는 것이 다르다.